Spring MVC是Spring公司在Servlet API基础上建立的原创Web框架。它提供了模型-视图-控制器架构,可用于开发灵活的Web应用。
在本教程中,我们将重点讨论与之相关的问题,因为它经常是Spring开发者求职面试的一个话题。
关于Spring框架的更多问题,你可以查看我们面试问题系列中另一篇与Spring有关的文章。
2.基础 Spring MVC 题
Q1. 为什么我们要使用Spring MVC?
Spring MVC实现了清晰的关注点分离,使我们能够轻松开发和单元测试我们的应用程序。
像如下概念:
- Dispatcher Servlet
- Controllers
- View Resolvers
- Views, Models
- ModelAndView
- Model and Session Attributes
是完全相互独立的,它们只负责一件事。
因此,MVC给了我们相当大的灵活性。它是基于接口的(有提供的实现类),我们可以通过使用自定义接口来配置框架的每一部分。
另一件重要的事情是,我们并没有被束缚在一个特定的视图技术上(例如JSP),而是可以选择我们最喜欢的技术。
另外,我们不只在Web应用开发中使用Spring MVC,在创建RESTful Web服务时也是如此。
Q2. @Autowired注解的作用是什么?
@Autowired注解可以与字段或方法一起使用,用于按类型注入Bean。这个注解允许Spring解析并将协作Bean注入你的Bean中。
更多细节,请参考关于@Autowired in Spring的教程。
Q3. 解释一下模型属性
@ModelAttribute注解是Spring MVC中最重要的注解之一。它将一个方法参数或方法返回值绑定到一个命名的模型属性上,然后将其暴露给Web视图。
如果我们在方法层面使用它,它表明该方法的目的是添加一个或多个模型属性。
另一方面,当作为方法参数使用时,它表示该参数应该从模型中获取。当不存在时,我们应该首先将其实例化,然后将其添加到模型中。一旦出现在模型中,我们应该从所有具有匹配名称的请求参数中填充参数字段。
关于这个注解的更多信息可以在我们与@ModelAttribute注解有关的文章中找到。
Q4. 解释一下@Controller和@RestController之间的区别?
@Controller和@RestController注释的主要区别在于,@RestController注解会自动包含@ResponseBody。这意味着我们不需要用@ResponseBody来标注我们的处理方法。如果我们想直接在HTTP响应体中写入响应类型,在@Controller类中需要这样做。
Q5. 描述一下PathVariable
我们可以使用@PathVariable注解处理方法的参数,来提取URI模板变量的值。
例如,如果我们想从www.mysite.com/user/123,通过id获取一个用户,我们应该把控制器中的方法映射为/user/{id}:
1 2 | |
@PathVariable只有一个名为value的元素。它是可选的,我们用它来定义URI模板变量的名称。如果我们省略value元素,那么URI模板变量的名称必须与方法参数名称相匹配。
也允许有多个@PathVariable注解,可以通过一个接一个地声明它们:
1 2 3 | |
或将它们全部放在一个Map<String, String>或MultiValueMap<String, String>中:
1 2 | |
Q6. 使用Spring MVC进行验证
Spring MVC默认支持JSR-303规范。我们需要在我们的Spring MVC应用中添加JSR-303及其实现的依赖性。例如,Hibernate Validator就是我们可以使用的JSR-303的实现之一。
JSR-303是用于bean验证的Java API规范,是Jakarta EE和JavaSE的一部分,它使用@NotNull、@Min和@Max等注解,确保bean的属性满足特定的标准。关于验证的更多信息,请参见Java Bean验证基础知识一文。
Spring提供了@Validator注解和BindingResult类。当我们有无效的数据时,Validator实现将在控制器的请求处理方法中触发错误。然后我们可以使用BindingResult类来获取这些错误。
除了使用现有的实现,我们还可以制作自己的实现。要做到这一点,我们首先创建一个符合JSR-303规范的注解。然后,我们实现Validator类。另一种方法是实现Spring的Validator接口,并通过控制器类中的@InitBinder注解将其设置为验证器。
要查看如何实现和使用你自己的验证器,请看关于Spring MVC中自定义验证的教程。
Q7. 什么是@RequestBody和@ResponseBody注解?
@RequestBody注解,作为处理方法参数使用,将HTTP请求主体与传输或域对象绑定。Spring使用Http消息转换器自动将传入的HTTP请求反序列化为Java对象。
当我们在Spring MVC控制器中的处理方法上使用@ResponseBody注解时,它表明我们将把该方法的返回类型直接写入HTTP响应体中。我们不会把它放在Model中,Spring也不会把它解释为视图名称。
请查看关于@RequestBody和@ResponseBody的文章,了解关于这些注解的更多细节。
Q8. 解释一下Model、ModelMap和ModelAndView?
Model接口定义了一个模型属性的持有人。ModelMap也有类似的目的,它能够传递一个值的集合。然后,它把这些值当作是在一个Map内。我们应该注意,在模型(ModelMap)中我们只能存储数据。我们把数据放进去并返回一个视图名称。
另一方面,在ModelAndView中,我们返回对象本身。我们把所有需要的信息,比如数据和视图名称,都设置在我们要返回的对象中。
你可以在关于Model、ModelMap和ModelView的文章中找到更多细节。
Q9. 解释SessionAttributes和SessionAttribute
@SessionAttributes注解是用来在用户会话中存储模型属性的。我们在控制器类中使用它,如我们关于Spring MVC中的会话属性的文章中所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
在前面的例子中,如果@ModelAttribute和@SessionAttributes有相同的名称属性,模型属性 “todos "将被添加到会话中。
如果我们想从一个全局管理的会话中获取现有的属性,我们将使用@SessionAttribute注解作为方法参数:
1 2 3 4 5 | |
Q10. @EnableWebMVC的目的是什么?
@EnableWebMvc注解的目的是通过Java配置启用Spring MVC。它等同于XML配置中的<mvc: annotation-driven>。这个注解从WebMvcConfigurationSupport导入Spring MVC配置。它能够支持@Controller注解的类,这些类使用@RequestMapping将传入的请求映射到处理方法。
你可以在我们的Spring @Enable注解指南中了解更多关于这个和类似注解的信息。
Q11. 什么是Spring中的ViewResolver?
ViewResolver通过将视图名称映射到实际视图,使应用程序能够在浏览器中渲染模型,这样无需将实现与特定的视图技术联系起来。
关于ViewResolver的更多细节,请看我们的Spring MVC中的ViewResolver指南。
Q12. 什么是BindingResult?
BindingResult是org.springframework.validation包中的一个接口,表示绑定结果。我们可以用它来检测和报告提交表单中的错误。它很容易被调用–我们只需要确保把它作为一个参数放在我们要验证的表单对象之后。可选的Model参数应该在BindingResult之后,这在自定义验证器教程中可以看到:
1 2 3 4 5 6 7 8 9 | |
当Spring看到@Valid注解时,它首先会尝试为被验证的对象找到验证器。然后,它将拾起验证注解并调用验证器。最后,它将把发现的错误放在BindingResult中,并把后者添加到视图模型中。
Q13. 什么是表单后备对象?
表单后备对象或命令对象只是一个POJO,它从我们要提交的表单中收集数据。
我们应该记住,它不包含任何逻辑,只包含数据。
要了解如何在Spring MVC中使用表单支持对象,请看我们关于Spring MVC中表单的文章。
Q14.@Qualifier注解的作用是什么?
它与@Autowired注解同时使用,以避免一个bean类型的多个实例出现时的混淆。
让我们看一个例子。我们在XML配置中声明了两个类似的Bean:
1 2 3 4 5 6 | |
当我们试图连接Bean时,我们会得到一个org.springframework.beans.factory.NoSuchBeanDefinitionException。为了解决这个问题,我们需要使用@Qualifier来告诉Spring关于哪个Bean应该被连接:
1 2 3 | |
Q15. @Required注解的作用是什么?
@Required注解用于setter方法,它表示在配置时必须填充具有该注解的bean属性。否则,Spring容器将抛出一个BeanInitializationException异常。
另外,@Required与@Autowired不同–因为它只限于 setter ,而@Autowired则不是。@Autowired也可以用来与构造函数和字段进行连接,而@Required只检查该属性是否被设置。
让我们看一个例子:
1 2 3 4 5 6 7 8 | |
现在,Person Bean的名字需要像这样在XML配置中设置:
1 2 3 | |
请注意,@Required默认情况下不能与基于Java的@Configuration类一起工作。如果你需要确保所有的属性都被设置,你可以在@Bean注解的方法中创建Bean时这样做。
译者点评:@Required 是如何实现的?
RequiredAnnotationBeanPostProcessor 通过检查 bean 定义中标注了 @Required 的属性是否有赋值来实现的。
Q16. 描述一下前台控制器模式
在前端控制器模式中,所有的请求将首先进入前端控制器,而不是Servlet。它将确保响应已经准备好,并将它们送回给浏览器。这样,我们就有一个地方可以控制来自外部世界的一切。
前端控制器将识别应该首先处理请求的Servlet。然后,当它从servlet那里得到数据后,它将决定渲染哪个视图,最后,它将把渲染好的视图作为一个响应发送回去:
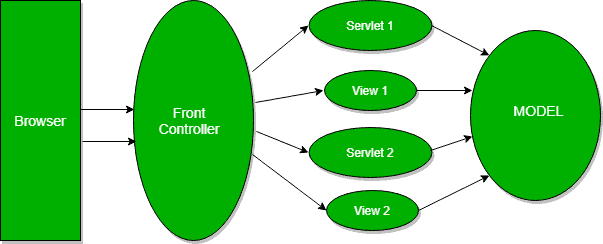
要查看实现细节,请查看我们的Java中的前端控制器模式指南。
Q17. 什么是 Model1和Model2的架构?
Model1和Model2代表了在设计Java Web应用时经常使用的两种设计模式。
在Model1中,一个请求被送到一个servlet或JSP那里进行处理。Servlet或JSP处理请求,处理业务逻辑,检索和验证数据,并生成响应:

由于这种架构很容易实现,我们通常在小型和简单的应用程序中使用它。
另一方面,它对于大规模的网络应用并不方便。这些功能通常在JSP中重复使用,其中业务和表现逻辑是耦合的。
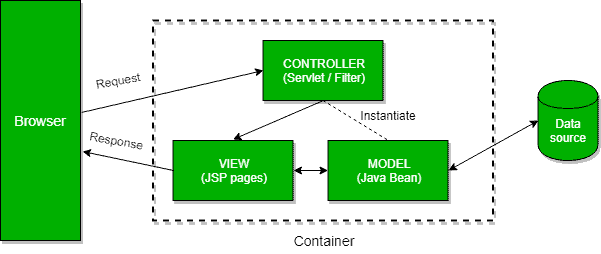
Model2是基于模型-视图-控制器设计模式的,它将视图与操作内容的逻辑分开。
此外,我们可以区分MVC模式中的三个模块:模型、视图和控制器。模型代表一个应用程序的动态数据结构。它负责数据和业务逻辑的操作。视图负责显示数据,而控制器作为前两者之间的接口。
在Model2中,一个请求被传递给控制器,控制器处理所需的逻辑,以便获得应该显示的正确内容。然后,控制器将内容放回请求中,通常是作为一个JavaBean或POJO。它还决定哪个视图应该渲染内容,最后将请求传递给它。然后,视图就会渲染数据:
3.进阶 Spring MVC 题
Q18. Spring中的@Controller、@Component、@Repository和@Service注解之间有什么区别?
根据Spring官方文档,@Component是任何Spring管理的组件的通用定型。@Repository、@Service和@Controller是@Component的特殊化,用于更具体的使用情况,例如,分别用于持久层、服务层和表现层。 让我们来看看后三者的具体使用情况:
- @Controller – 表示该类扮演着控制器的角色,并在该类中检测@RequestMapping注解
- @Service – 表示该类持有业务逻辑并调用存储库层的方法
- @Repository – 表示该类定义了一个数据存储库;它的工作是捕捉平台特定的异常,并将其作为Spring统一的未检查的异常之一重新抛出
Q19. 什么是DispatcherServlet和ContextLoaderListener?
简单地说,在前端控制器设计模式中,一个控制器负责将传入的HttpRequests引导到应用程序的所有其他控制器和处理程序。
Spring的DispatcherServlet实现了这种模式,因此,它负责正确协调HttpRequests到正确的处理程序。
另一方面,ContextLoaderListener启动和关闭了Spring的根WebApplicationContext。它将ApplicationContext的生命周期与ServletContext的生命周期联系起来。我们可以用它来定义在不同Spring上下文中工作的共享bean。
关于DispatcherServlet的更多细节,请参考本教程。
Q20. 什么是MultipartResolver,我们什么时候应该使用它?
MultipartResolver接口是用来上传文件的。Spring框架提供了一个使用Commons FileUpload 的 MultipartResolver实现,另一个使用Servlet 3.0多部分请求解析。
使用这些,我们可以在我们的Web应用程序中支持文件上传。
Q21. 什么是Spring MVC拦截器以及如何使用它?
Spring MVC拦截器允许我们拦截一个客户端请求,并在三个地方进行处理–在处理之前、处理之后或完成之后(当视图被渲染时)。 拦截器可以用于跨领域的关注,避免重复的处理程序代码,如记录、改变Spring模型中全局使用的参数等。
关于细节和各种实现,请看Spring MVC HandlerInterceptor介绍这篇文章。
Q22. 什么是Init Binder?
一个用@InitBinder注解的方法被用来定制一个请求参数、URI模板和后备/命令对象。我们在控制器中定义它,它有助于控制请求。在这个方法中,我们注册和配置我们的自定义PropertyEditors,格式化器和验证器。
注解中有'value'元素。如果我们不设置它,@InitBinder注解的方法将在每个HTTP请求中被调用。如果我们设置了这个值,这些方法将只适用于特定的命令/表单属性,与/或名称与'value'元素对应的请求参数。
重要的是要记住,其中一个参数必须是WebDataBinder。其他参数可以是处理方法支持的任何类型,除了命令/表单对象和相应的验证结果对象。
Q23. 解释一下控制器增强
@ControllerAdvice注解允许我们编写适用于大范围控制器的全局代码。我们可以将控制器的范围与选定的包或特定的注解联系起来。
默认情况下,@ControllerAdvice适用于用@Controller(或@RestController)注释的类。如果我们想更具体一些,我们还有一些属性可以使用。
如果我们想把适用的类限制在一个包内,我们应该在注释中加入包的名字:
1 2 3 | |
也可以使用多个包,但这次我们需要使用一个数组而不是String。
除了通过包的名字限制到包之外,我们还可以通过使用该包中的一个类或接口来实现:
1
| |
“assignableTypes"元素将@ControllerAdvice应用于特定的类,而 "annotations"则是针对特定的注释。
值得注意的是,我们应该把它和@ExceptionHandler一起使用。这种组合将使我们能够配置一个全局的、更具体的错误处理机制,而不需要每次都为每个控制器类实现它。
Q24. @ExceptionHandler注解的作用是什么?
@ExceptionHandler注解允许我们定义一个处理异常的方法。我们可以独立使用该注解,但将其与@ControllerAdvice一起使用是更好的选择。因此,我们可以建立一个全局性的错误处理机制。这样一来,我们就不需要在每个控制器中编写异常处理的代码。
让我们看看Spring的REST错误处理这篇文章中的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
我们还应该注意,这将为所有抛出IllegalArgumentException或IllegalStateException的控制器提供@ExceptionHandler方法。用@ExceptionHandler声明的异常应该与作为方法参数的异常相匹配。否则,异常解析机制将在运行时失败。
这里需要记住的一点是,为同一个异常定义多个@ExceptionHandler是可能的。但我们不能在同一个类中这样做,因为Spring会通过抛出一个异常并在启动时失败来抱怨。
另一方面,如果我们在两个独立的类中定义这些,应用程序就会启动,但它会使用它找到的第一个处理程序,可能是错误的。
Q25. Web应用中的异常处理
在Spring MVC中,我们有三种处理异常的方法。
- 每个异常
- 每个控制器
- 全局
如果在Web请求处理过程中抛出一个未处理的异常,服务器将返回一个HTTP 500响应。为了防止这种情况,我们应该用@ResponseStatus注解来注释我们的任何自定义异常。这类异常由HandlerExceptionResolver来解决。
当一个控制器方法抛出我们的异常时,这将导致服务器以指定的状态码返回一个适当的HTTP响应。我们应该记住,我们不应该在其他地方处理我们的异常,这种方法才会有效。
另一种处理异常的方法是使用@ExceptionHandler注解。我们在任何控制器中添加@ExceptionHandler方法,用它们来处理从该控制器中抛出的异常。这些方法可以在没有@ResponseStatus注解的情况下处理异常,将用户重定向到一个专门的错误视图,或者建立一个完全自定义的错误响应。
我们也可以传入与Servlet相关的对象(HttpServletRequest, HttpServletResponse, HttpSession, 和Principal)作为处理方法的参数。但是,我们应该记住,我们不能把模型对象直接作为参数。
处理错误的第三个选择是通过@ControllerAdvice类。它将允许我们应用同样的技术,只是这次是在应用层面,而不仅仅是在特定的控制器上。为了实现这一点,我们需要同时使用@ControllerAdvice和@ExceptionHandler。这样,异常处理程序将处理任何控制器抛出的异常。
关于这个话题的更多详细信息,请浏览Spring的REST错误处理文章。
译者点评:Spring 官方博客的这篇Exception Handling in Spring MVC,对 Spring MVC 的异常处理介绍的很全面,值得反复研读。
4. 结论
在这篇文章中,我们已经探讨了一些Spring MVC相关的问题,这些问题可能会在Spring开发者的技术面试中出现。你应该把这些问题作为进一步研究的起点,因为这绝不是一个详尽的列表。
我们祝愿你在即将到来的面试中有好运气!